
Pengantar
Di era digital saat ini, data adalah aset yang sangat berharga. Hampir semua informasi tersedia di internet, mulai dari berita, harga produk, profil bisnis, lowongan kerja, hingga tren media sosial. Untuk mengumpulkan data tersebut secara otomatis, dikenal beberapa istilah penting seperti crawling, scraping, dan spidering.
Sayangnya, banyak orang masih menganggap ketiganya sama. Padahal, meskipun saling berkaitan, crawling, scraping, dan spidering memiliki fungsi, tujuan, dan cara kerja yang berbeda. Kesalahan memahami istilah ini dapat membuat seseorang salah memilih pendekatan ketika membangun aplikasi pencari data, web crawler, mesin pencari, sistem monitoring, atau proyek data mining.
Lalu, apa sebenarnya perbedaan crawling, scraping, dan spidering? Kapan masing-masing teknik digunakan? Artikel ini akan membahasnya secara lengkap, sederhana, dan mudah dipahami.
Mengapa Penting Memahami Perbedaan Ketiganya?
Sebelum masuk ke definisi teknis, kita perlu memahami dulu kenapa istilah-istilah ini penting.
Bayangkan kamu ingin membangun:
- mesin pencari berita lokal
- website agregator properti
- monitor harga produk marketplace
- sistem intelijen ancaman siber
- dashboard monitoring kompetitor
- aplikasi pencari lowongan kerja
- data warehouse konten dari banyak situs
Jika tujuanmu adalah menelusuri banyak halaman website, maka pendekatannya berbeda dibanding saat kamu ingin mengambil data spesifik dari satu halaman tertentu.
Di sinilah peran tiga istilah ini menjadi sangat penting:
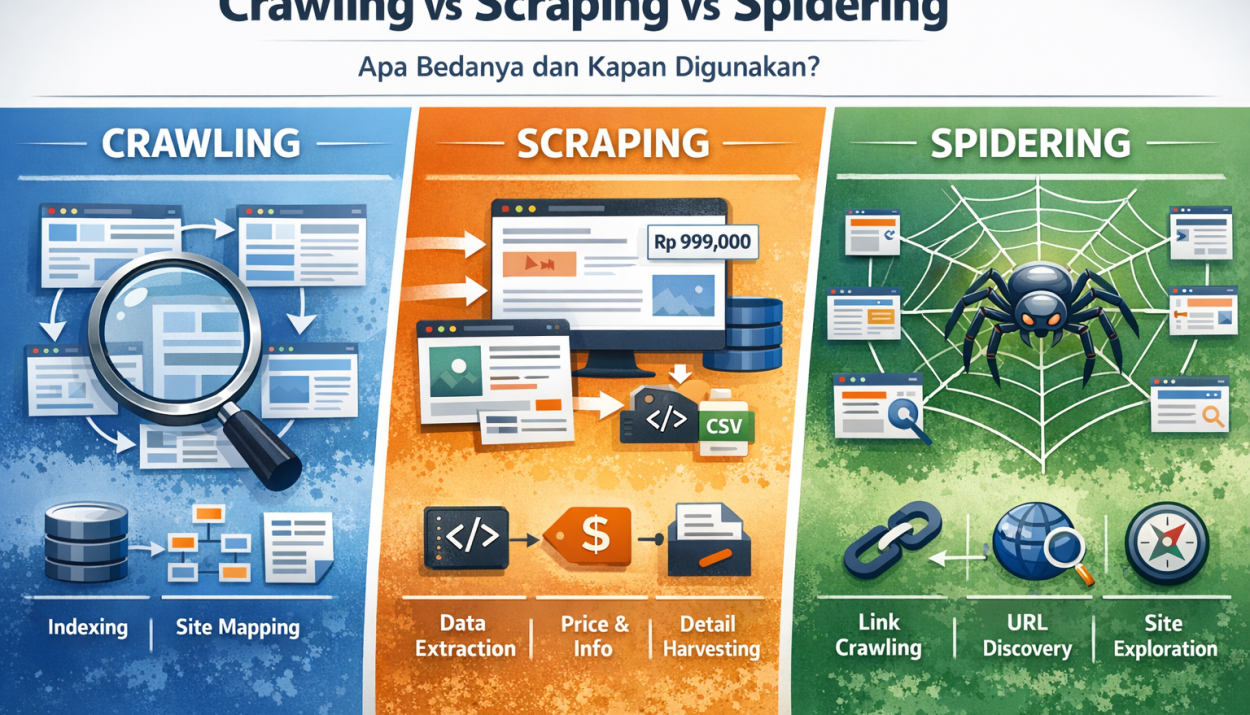
- Spidering → fokus menjelajahi web
- Crawling → fokus menemukan dan mengindeks banyak halaman
- Scraping → fokus mengambil data tertentu dari halaman web
Mereka sering bekerja bersama, tetapi tidak identik.
1. Apa Itu Spidering?
Definisi Spidering
Spidering adalah proses menjelajahi halaman-halaman web secara otomatis dengan mengikuti tautan (link) dari satu halaman ke halaman lain.
Istilah ini berasal dari kata “spider”, yaitu program otomatis yang “merayap” di web layaknya laba-laba yang bergerak di antara jaring-jaring tautan internet.
Dalam praktiknya, spidering biasanya digunakan untuk:
- menemukan halaman baru
- memetakan struktur website
- mengikuti hyperlink secara sistematis
- menelusuri hubungan antarhalaman
Cara Kerja Spidering
Spider biasanya bekerja seperti ini:
- Memulai dari satu URL awal (seed URL)
- Mengunduh halaman tersebut
- Membaca semua tautan yang ada di halaman
- Mengunjungi tautan-tautan itu satu per satu
- Mengulangi proses yang sama secara terus-menerus
Contoh sederhananya:
Kamu punya URL awal:
https://contohwebsite.com
Spider akan:
- membuka homepage
- menemukan link ke halaman berita
- menemukan link ke artikel-artikel
- menemukan link ke kategori
- terus bergerak mengikuti struktur situs
Tujuan Utama Spidering
Spidering biasanya digunakan untuk:
- eksplorasi website
- pemetaan struktur halaman
- menemukan URL baru
- membangun graph link antarhalaman
- mendukung crawling skala besar
Contoh Penggunaan Spidering
- Mesin pencari seperti Google menggunakan spider untuk menjelajahi internet
- Sistem cyber threat intelligence menjelajahi forum, situs, dan halaman publik
- Aplikasi monitoring konten menemukan artikel baru dari website berita
Karakteristik Spidering
Spidering umumnya:
- fokus pada navigasi antarhalaman
- belum tentu mengambil data spesifik
- sangat bergantung pada link
- sering menjadi tahap awal sebelum crawling atau scraping
2. Apa Itu Crawling?
Definisi Crawling
Crawling adalah proses mengakses, menelusuri, dan mengumpulkan banyak halaman web secara otomatis untuk tujuan indeksasi, pemetaan, atau pengumpulan informasi skala besar.
Jika spidering lebih identik dengan “menjelajahi”, maka crawling lebih luas karena mencakup:
- penelusuran halaman
- pengumpulan konten
- penyimpanan metadata
- pengelolaan antrian URL
- pengindeksan halaman
Dengan kata lain, spidering sering dianggap sebagai bagian dari crawling.
Cara Kerja Crawling
Crawler biasanya bekerja seperti ini:
- Memiliki daftar URL awal
- Mengunjungi URL tersebut
- Menyimpan konten atau metadata halaman
- Mengekstrak link dari halaman
- Menambahkan link baru ke antrian
- Mengunjungi halaman berikutnya
- Mengulang proses hingga batas tertentu
Crawler modern biasanya juga memperhatikan:
robots.txt- sitemap XML
- canonical URL
- status HTTP (200, 404, 301, dll)
- duplikasi konten
- batas kecepatan request
- kedalaman halaman (crawl depth)
Tujuan Utama Crawling
Crawling biasanya digunakan untuk:
- mengumpulkan banyak halaman web
- membangun index mesin pencari
- mengarsipkan konten
- mendeteksi perubahan halaman
- monitoring website secara otomatis
- mengumpulkan data dari banyak sumber
Contoh Penggunaan Crawling
Beberapa contoh nyata crawling:
1. Mesin Pencari
Google, Bing, dan mesin pencari lain melakukan crawling untuk menemukan halaman baru dan memperbarui index mereka.
2. Website Agregator Berita
Sebuah portal berita otomatis dapat melakukan crawling ke ratusan website media untuk mengambil daftar artikel terbaru.
3. Marketplace Monitoring
Sistem crawling dapat memantau banyak halaman kategori dan produk untuk mendeteksi perubahan harga atau stok.
4. Cybersecurity & OSINT
Dalam dunia keamanan siber, crawling dipakai untuk mengumpulkan informasi publik dari website, forum, direktori, dan sumber intelijen terbuka lainnya.
Karakteristik Crawling
Crawling biasanya:
- bekerja pada banyak halaman
- fokus pada cakupan (coverage)
- sering melibatkan database
- cocok untuk otomasi skala besar
- dapat menggabungkan spidering dan scraping
3. Apa Itu Scraping?
Definisi Scraping
Scraping adalah proses mengambil data tertentu dari halaman web secara otomatis.
Kalau crawling fokus pada menelusuri banyak halaman, maka scraping fokus pada isi data di dalam halaman.
Misalnya, dari satu halaman produk, kamu ingin mengambil:
- nama produk
- harga
- deskripsi
- rating
- gambar
- stok
- kategori
Itulah scraping.
Cara Kerja Scraping
Scraper biasanya bekerja seperti ini:
- Mengakses halaman web tertentu
- Membaca struktur HTML halaman
- Menemukan elemen yang diinginkan
- Mengekstrak data dari elemen tersebut
- Menyimpan hasilnya ke database, CSV, JSON, atau API
Contohnya:
Dari halaman artikel berita, scraper bisa mengambil:
- judul artikel
- isi artikel
- nama penulis
- tanggal publikasi
- kategori
- tag
Tujuan Utama Scraping
Scraping digunakan untuk:
- mengambil data terstruktur
- mengubah data web menjadi dataset
- mengisi database secara otomatis
- monitoring konten atau harga
- migrasi atau agregasi data
Contoh Penggunaan Scraping
1. Scraping Harga Produk
Mengambil harga produk dari banyak e-commerce untuk perbandingan harga.
2. Scraping Artikel Berita
Mengambil judul, isi, dan metadata artikel dari berbagai portal berita.
3. Scraping Lowongan Kerja
Mengambil posisi, perusahaan, lokasi, dan deskripsi pekerjaan dari situs karier.
4. Scraping Data Properti
Mengambil harga rumah, lokasi, luas bangunan, dan kontak agen dari website properti.
Karakteristik Scraping
Scraping biasanya:
- fokus pada data spesifik
- bekerja berdasarkan struktur HTML/DOM
- sangat bergantung pada selector
- sering digunakan setelah crawling
4. Hubungan Spidering, Crawling, dan Scraping
Agar lebih mudah dipahami, bayangkan kamu sedang mencari buku di perpustakaan:
- Spidering = berjalan menyusuri rak dan lorong untuk menemukan lokasi buku
- Crawling = mencatat semua rak, kategori, dan buku yang tersedia
- Scraping = membuka buku tertentu lalu mencatat judul, penulis, dan isi pentingnya
Jadi hubungan ketiganya seperti ini:
Spidering → Crawling → Scraping
Urutannya sering terjadi seperti berikut:
- Spidering menemukan halaman-halaman baru
- Crawling mengumpulkan dan mengelola banyak halaman
- Scraping mengambil data spesifik dari halaman yang telah ditemukan
Namun dalam beberapa kasus, kamu bisa langsung melakukan scraping tanpa crawling terlebih dahulu — misalnya jika kamu sudah tahu URL yang ingin diambil.
5. Perbedaan Crawling vs Scraping vs Spidering
Berikut perbedaan utamanya:
A. Berdasarkan Tujuan
- Spidering: menemukan dan mengikuti link
- Crawling: menelusuri dan mengumpulkan banyak halaman
- Scraping: mengambil data spesifik dari halaman
B. Berdasarkan Fokus
- Spidering: navigasi
- Crawling: cakupan halaman
- Scraping: ekstraksi data
C. Berdasarkan Output
- Spidering: daftar link / peta struktur
- Crawling: koleksi halaman / metadata / index
- Scraping: data terstruktur (judul, harga, isi, dll)
D. Berdasarkan Kompleksitas
- Spidering: relatif sederhana
- Crawling: lebih kompleks karena melibatkan antrian, deduplikasi, dan skala
- Scraping: kompleks jika struktur HTML dinamis atau anti-bot kuat
Tabel Perbandingan
| Aspek | Spidering | Crawling | Scraping |
|---|---|---|---|
| Fungsi utama | Menjelajahi link | Mengumpulkan banyak halaman | Mengambil data spesifik |
| Fokus | Navigasi | Penelusuran & indeksasi | Ekstraksi data |
| Output | URL / struktur situs | Halaman / metadata / index | Data terstruktur |
| Skala | Kecil hingga besar | Umumnya besar | Bisa kecil atau besar |
| Ketergantungan | Hyperlink | URL, link, queue | HTML, DOM, selector |
| Cocok untuk | Eksplorasi situs | Search engine, monitoring | Data mining, analitik |
6. Kapan Harus Menggunakan Spidering?
Gunakan spidering ketika tujuanmu adalah:
- menemukan semua halaman dalam sebuah website
- memetakan struktur situs
- menelusuri kategori dan subkategori
- mencari URL artikel, produk, atau halaman detail
- membangun daftar tautan untuk tahap selanjutnya
Contoh Kasus
Kamu ingin membuat sistem yang mencari semua artikel dari situs berita.
Langkah pertama:
- spider homepage
- temukan halaman kategori
- temukan halaman artikel
- simpan semua URL artikel
Di sini, spidering sangat berguna.

7. Kapan Harus Menggunakan Crawling?
Gunakan crawling ketika kamu ingin:
- mengambil banyak halaman dari banyak website
- mengarsipkan konten
- membuat search engine internal
- memantau perubahan konten secara berkala
- membangun sistem agregator data
Contoh Kasus
Kamu ingin membuat:
- portal berita otomatis
- mesin pencari artikel lokal
- sistem pemantauan harga
- arsip halaman web
Maka kamu memerlukan crawler yang:
- mengelola antrian URL
- menyimpan metadata
- menghindari duplikasi
- melakukan crawling berkala
8. Kapan Harus Menggunakan Scraping?
Gunakan scraping ketika kamu ingin mengambil data spesifik seperti:
- judul artikel
- isi berita
- harga produk
- alamat bisnis
- nomor telepon
- rating
- spesifikasi barang
- daftar lowongan kerja
Contoh Kasus
Kamu sudah punya URL artikel berita seperti:
https://contoh.com/berita/123
Sekarang kamu ingin mengambil:
- judul
- isi
- penulis
- tanggal
Maka yang kamu butuhkan adalah scraping, bukan crawling.
9. Studi Kasus Nyata: Portal Berita Otomatis
Agar lebih jelas, mari lihat contoh proyek nyata.
Tujuan
Membangun website yang mengumpulkan berita dari banyak media online di Indonesia.
Bagaimana Spidering, Crawling, dan Scraping Digunakan?
Tahap 1 – Spidering
Sistem menelusuri:
- homepage media
- kategori berita
- daftar artikel terbaru
Tujuannya: menemukan URL artikel.
Tahap 2 – Crawling
Sistem mengakses ratusan atau ribuan URL artikel dari berbagai situs.
Tujuannya:
- mengumpulkan halaman
- menyimpan status
- mengelola jadwal update
- menghindari artikel duplikat
Tahap 3 – Scraping
Sistem mengambil data dari tiap artikel:
- judul
- isi
- penulis
- tanggal terbit
- gambar utama
- kategori
Lalu semua data dimasukkan ke database dan ditampilkan di website.
Kesimpulan dari Studi Kasus
Satu proyek sering kali membutuhkan ketiganya sekaligus.
10. Tools yang Umum Digunakan
Berikut beberapa tools populer yang sering dipakai untuk crawling, scraping, dan spidering.
Untuk Spidering & Crawling
- Scrapy
- Heritrix
- Apache Nutch
- StormCrawler
- wget
- httrack
Untuk Scraping
- BeautifulSoup
- lxml
- Selenium
- Playwright
- Puppeteer
- Cheerio
- Jsoup
Untuk Website Dinamis
Jika website menggunakan JavaScript berat, scraping biasa kadang tidak cukup. Kamu mungkin perlu:
- Playwright
- Selenium
- Puppeteer
Karena data baru muncul setelah halaman dirender di browser.
11. Tantangan dalam Crawling dan Scraping
Meskipun terdengar sederhana, implementasi di dunia nyata tidak selalu mudah.
A. Struktur HTML Berubah
Website bisa mengubah class, id, atau layout sewaktu-waktu. Ini bisa membuat scraper gagal.
B. Anti-Bot Protection
Banyak website memiliki perlindungan seperti:
- rate limiting
- CAPTCHA
- Cloudflare
- bot detection
- session validation
C. Duplikasi Data
Crawler bisa mengunjungi halaman yang sama berkali-kali jika tidak ada sistem deduplikasi.
D. JavaScript Rendering
Tidak semua konten langsung tersedia di HTML awal. Banyak data dimuat setelah JavaScript berjalan.
E. Skala
Meng-crawl ribuan atau jutaan halaman membutuhkan:
- queue management
- concurrency control
- penyimpanan efisien
- error handling
- retry mechanism
12. Etika dan Legalitas: Jangan Asal Scraping
Ini bagian yang sering diabaikan.
Hanya karena data ada di internet bukan berarti semua data bebas diambil sesuka hati.
Hal yang Harus Diperhatikan
Sebelum melakukan crawling atau scraping, perhatikan:
- robots.txt
- Terms of Service
- hak cipta konten
- privasi data
- beban server target
- izin penggunaan data
Praktik yang Baik
Agar lebih etis dan aman:
- gunakan jeda request (
delay) - batasi concurrency
- hormati
robots.txt - hindari scraping data sensitif
- jangan menyerang server dengan request berlebihan
- simpan hanya data yang memang dibutuhkan
Dalam konteks profesional, web scraping yang baik bukan sekadar berhasil mengambil data, tetapi juga dilakukan secara bertanggung jawab.
13. Mana yang Harus Dipelajari Dulu?
Kalau kamu masih pemula, urutan belajar terbaik adalah:
1. Mulai dari Scraping
Kenapa? Karena lebih mudah dipahami.
Belajarlah:
- HTML dasar
- CSS selector
- XPath
- HTTP request
- parsing HTML
2. Lanjut ke Spidering
Setelah paham mengambil data dari satu halaman, pelajari cara:
- menemukan link
- mengikuti pagination
- menelusuri kategori
3. Naik ke Crawling
Tahap ini lebih advanced karena kamu akan belajar:
- queue
- scheduler
- deduplikasi
- penyimpanan data
- crawling distributed
- fault tolerance
14. Ringkasan Singkat
Agar mudah diingat:
- Spidering = mencari dan mengikuti link
- Crawling = menelusuri dan mengumpulkan banyak halaman
- Scraping = mengambil data spesifik dari halaman
Atau dalam satu kalimat:
Spidering menemukan jalan, crawling menjelajahi wilayah, scraping mengambil isi yang dibutuhkan.
15. Kesimpulan
Istilah crawling, scraping, dan spidering memang sering digunakan secara bergantian, tetapi sebenarnya mereka memiliki peran yang berbeda dalam proses pengumpulan data web.
- Spidering berfokus pada penelusuran tautan dan penemuan halaman
- Crawling berfokus pada pengumpulan banyak halaman dalam skala besar
- Scraping berfokus pada ekstraksi data spesifik dari halaman web
Dalam praktiknya, ketiganya sering digunakan secara berurutan dan saling melengkapi. Jika kamu ingin membangun aplikasi seperti mesin pencari, portal berita otomatis, agregator properti, monitoring harga, atau sistem intelijen web, maka memahami ketiganya adalah fondasi yang sangat penting.
Memahami perbedaan ini akan membantu kamu:
- memilih tools yang tepat
- merancang arsitektur data yang efisien
- membangun sistem otomasi web yang lebih stabil
- menghindari kesalahan konsep dalam proyek data extraction
Pada akhirnya, pertanyaan “mana yang lebih penting?” sebenarnya kurang tepat.
Karena jawabannya adalah:
Bukan memilih salah satu, tetapi memahami kapan harus menggunakan masing-masing.
FAQ (Opsional untuk SEO)
Apakah crawling sama dengan scraping?
Tidak. Crawling digunakan untuk menelusuri dan mengumpulkan banyak halaman, sedangkan scraping digunakan untuk mengambil data spesifik dari halaman tersebut.
Apa itu spider dalam web scraping?
Spider adalah bot atau program otomatis yang menjelajahi website dengan mengikuti link dari satu halaman ke halaman lain.
Kapan saya harus menggunakan scraping?
Gunakan scraping ketika kamu ingin mengambil data tertentu seperti judul artikel, harga produk, alamat bisnis, atau isi halaman.
Apakah scraping legal?
Tergantung konteksnya. Legalitas scraping dipengaruhi oleh Terms of Service, hak cipta, privasi data, dan aturan penggunaan website target.
Apa tools terbaik untuk crawling dan scraping?
Beberapa tools populer adalah Scrapy, BeautifulSoup, Selenium, Playwright, Puppeteer, dan Apache Nutch.










