
Pengantar
Seiring meningkatnya adopsi kecerdasan buatan dalam berbagai aplikasi—mulai dari chatbot hingga analisis dokumen—tantangan utama yang sering muncul adalah akurasi dan relevansi jawaban. Model AI berbasis large language model (LLM) memiliki kemampuan generatif yang tinggi, namun tetap bergantung pada data pelatihan yang bersifat statis. Untuk menjawab keterbatasan tersebut, muncullah pendekatan Retrieval-Augmented Generation (RAG).
RAG mengombinasikan kemampuan pencarian informasi dengan generasi teks, sehingga sistem AI dapat memberikan jawaban yang lebih kontekstual dan berbasis data terkini.
Apa Itu Retrieval-Augmented Generation?
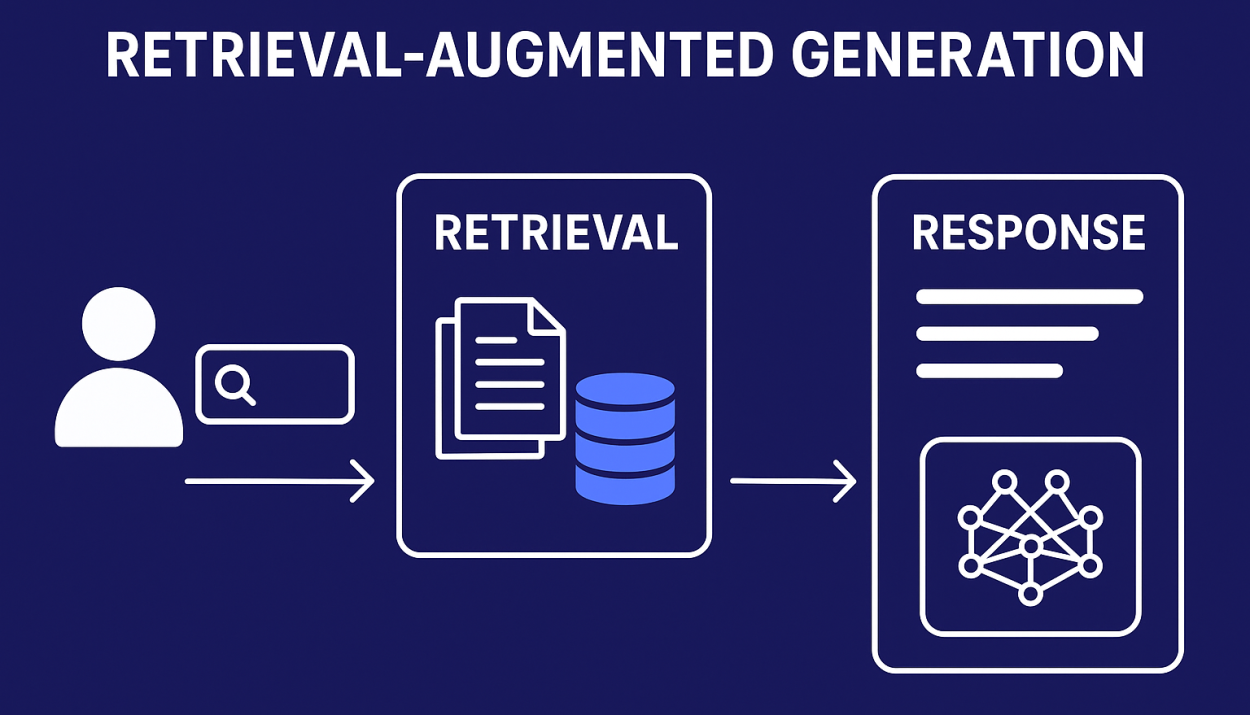
Retrieval-Augmented Generation adalah arsitektur AI yang menggabungkan dua proses utama:
-
Retrieval – mengambil data relevan dari sumber eksternal
-
Generation – menghasilkan jawaban berdasarkan data yang telah diambil
Alih-alih hanya mengandalkan pengetahuan internal model, RAG memungkinkan AI mengakses dokumen, database, atau indeks vektor secara real-time.
Menurut penelitian Facebook AI Research, RAG dirancang untuk meningkatkan factual consistency dan mengurangi kesalahan informasi pada model generatif (dikutip dari Facebook AI Research).
Arsitektur Teknis RAG
1. Data Source
Sumber data bisa berupa dokumen teks, database internal, knowledge base, atau API eksternal.
2. Embedding dan Vector Database
Dokumen diubah menjadi vektor numerik menggunakan model embedding, lalu disimpan dalam vector database seperti FAISS atau Milvus.
3. Retriever
Retriever bertugas mencari potongan data paling relevan berdasarkan query pengguna.
4. Generator (LLM)
Model bahasa besar menghasilkan jawaban dengan memanfaatkan konteks hasil retrieval.
Mengapa RAG Penting dalam Sistem AI?
Pendekatan RAG memberikan beberapa keunggulan teknis, antara lain:
-
Akurasi Lebih Tinggi
Jawaban didasarkan pada data aktual, bukan sekadar pola bahasa. -
Reduksi Hallucination
AI lebih kecil kemungkinannya menghasilkan informasi yang tidak benar. -
Data Lebih Mudah Diperbarui
Tidak perlu melatih ulang model setiap kali data berubah. -
Kustomisasi Konteks
Cocok untuk domain spesifik seperti hukum, kesehatan, atau dokumentasi internal.
Perbedaan RAG dan Fine-Tuning
RAG sering dibandingkan dengan fine-tuning, namun keduanya memiliki pendekatan berbeda:
-
Fine-Tuning: Memasukkan pengetahuan baru ke dalam model
-
RAG: Mengambil pengetahuan dari luar model saat inferensi
Dalam praktiknya, RAG lebih fleksibel untuk sistem yang membutuhkan pembaruan data secara cepat dan dinamis.
Tantangan Implementasi RAG
Meski menawarkan banyak manfaat, RAG juga memiliki tantangan teknis:
-
Kualitas embedding sangat memengaruhi hasil retrieval
-
Latensi meningkat karena proses pencarian tambahan
-
Perlu pengelolaan data dan indeks yang baik
-
Risiko informasi usang jika data source tidak diperbarui
Optimalisasi pipeline menjadi kunci keberhasilan implementasi RAG.
Penerapan RAG dalam Dunia Nyata
RAG banyak digunakan pada:
-
Chatbot berbasis dokumen internal
-
Sistem pencarian cerdas
-
Asisten virtual perusahaan
-
Analisis laporan dan dokumen besar
Perusahaan teknologi besar mulai mengadopsi RAG sebagai standar untuk sistem AI berbasis pengetahuan.
Kesimpulan
Retrieval-Augmented Generation menghadirkan pendekatan yang lebih andal dalam membangun sistem AI yang akurat dan kontekstual. Dengan menggabungkan kemampuan pencarian dan generasi teks, RAG mampu menjembatani keterbatasan model generatif murni.




: Cara Menghubungkan Data Internal Perusahaan dengan LLM agar Jawaban Lebih Akurat dan Minim Halusinasi")




